Deposit Customer Predictions using KNN
Project Overview
This project focuses on predicting whether a prospective customer would sign up as a deposit customer at a banking institution in Portugal based on data collected from a marketing campaign conducted via phone calls.
Project Description
In this project, I tackled the challenge of predicting whether a prospective customer would sign up as a deposit customer at a banking institution in Portugal. The data was collected from a marketing campaign conducted via phone calls, and the goal was to build a model that could accurately predict which prospects would convert to deposit customers.
The dataset contained various customer attributes and campaign information, which I used to train a K-Nearest Neighbors (KNN) classifier. One of the key challenges in this project was dealing with imbalanced data, as the number of customers who signed up for deposits was significantly smaller than those who did not.
I experimented with different distance metrics (Euclidean and Manhattan) and various values of k (number of neighbors) to find the optimal model configuration. The project involved comprehensive data preprocessing, feature selection, model training, and evaluation.
Distance Metric Comparison
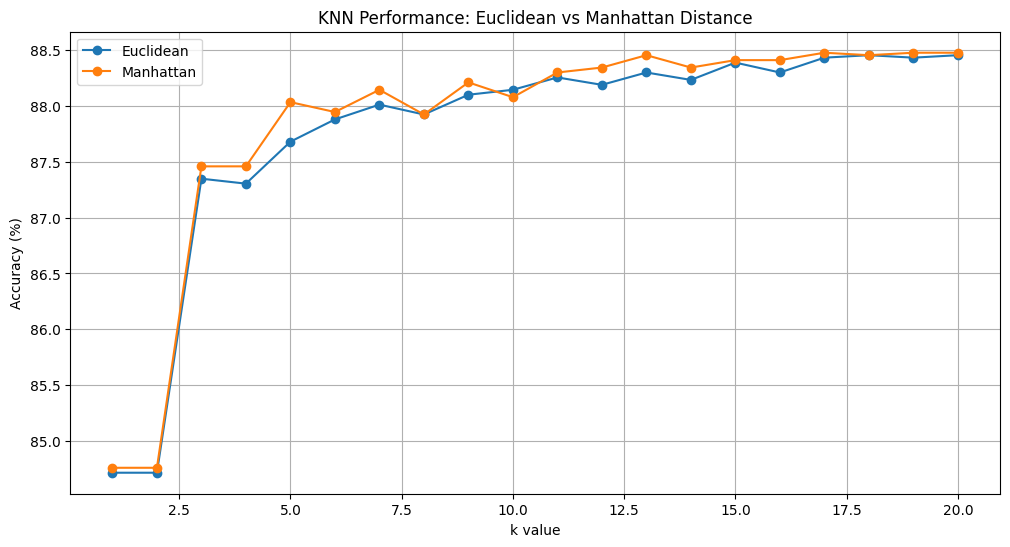
Comparison of KNN performance using Euclidean vs Manhattan distance metrics across different k values
The graph above shows the performance comparison between Euclidean and Manhattan distance metrics for different k values. Both metrics start with lower accuracy around 84.5-85% for k=2, then jump to about 87.5% at k=3-4, and gradually improve as k increases, eventually reaching around 88.5% accuracy at k=20.
Interestingly, the Manhattan distance metric (orange line) generally performs slightly better than Euclidean distance (blue line) across most k values. This suggests that for this particular dataset, the Manhattan distance might be more suitable for capturing the relationships between data points.
Results and Evaluation
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Class 0 (No Deposit) | 0.93 | 0.91 | 0.92 | 1266 |
| Class 1 (Deposit) | 0.30 | 0.36 | 0.33 | 138 |
| Accuracy | 0.8568 (85.68%) | 1404 | ||
| Macro Avg | 0.62 | 0.63 | 0.62 | 1404 |
| Weighted Avg | 0.87 | 0.86 | 0.86 | 1404 |
Performance Analysis
From the evaluation metrics, it's clear that the model performs well for predicting customers who will not become deposit customers (Class 0), with high precision (0.93), recall (0.91), and F1-score (0.92). However, the model struggles to accurately predict customers who will become deposit customers (Class 1), with much lower precision (0.30), recall (0.36), and F1-score (0.33).
This imbalance in performance is largely due to the class imbalance in the dataset, with only 138 positive examples (deposit customers) compared to 1266 negative examples (non-deposit customers). The overall accuracy of 85.68% is somewhat misleading because it's heavily influenced by the model's good performance on the majority class.
The macro average metrics (precision: 0.62, recall: 0.63, F1-score: 0.62) provide a more balanced view of the model's performance across both classes, showing that there's significant room for improvement, especially for predicting the minority class.
Conclusion and Future Work
This project demonstrates the application of the K-Nearest Neighbors algorithm to a real-world banking problem. While the model achieves good overall accuracy, it struggles with the class imbalance issue, which is common in many real-world datasets.
For future work, several approaches could be explored to improve the model's performance on the minority class:
- Implementing resampling techniques such as SMOTE (Synthetic Minority Over-sampling Technique) to address the class imbalance
- Exploring feature engineering to create more discriminative features for the minority class
- Testing other classification algorithms that might handle imbalanced data better, such as ensemble methods
- Using different evaluation metrics like ROC-AUC or PR-AUC that are more suitable for imbalanced datasets
Despite these challenges, the current model provides valuable insights for the banking institution's marketing team, helping them identify potential deposit customers more efficiently than random targeting.